电话机器人http接口说明
介绍
这个接口是基于cti模块实现的类似smartivr接口(可以称呼为新一代smartivr接口。),但是这个接口更简单易用,smartivr接口已经逐步停止升级,所有使用smartivr接口开发的程序,都建议迁移到这个接口来。
拨号方案配置
<action application="cti_robot" data="http://49.235.127.246/flow.php?a=${destination_number}"/> |
接口回调流程
开始流程(create),进入机器人第一个执行的回调。
cti –> web (请求)
{
"timestamp": 1658152564098414,
"call_source": "",
"source_name": "",
"callid": "27d36dee-a03f-40d2-b92e-2872c9057c21",
"appid": "451f16c4-6795-4976-a8c0-0f6c255dd9ac",
"method": "create"
}
- timestamp 请求的时间戳
- call_source 呼叫来源 ,比如队列外呼就是 queuedialer
- source_name 来源名称 ,比如队列外呼就是任务名称
- callid 通话唯一UUID
- appid 执行动作的UUID,每次需要执行新动作系统会预先生成UUID,后续的输入都会带上这个UUID,动作执行完成时就会生成新的UUID。
- method 方法
web –> cti (响应)
{
"action": "cti_play_and_detect_speech",
"argument": "'1' '32' '0' '0.3' '127.0.0.1:9988' '120' '800' '5000' '20000' '' '' '451f16c4-6795-4976-a8c0-0f6c255dd9ac' '1' '${strftime(%Y-%m-%d)}' 'wav'",
"tts": {
"ttsurl": "http://127.0.0.1:9989/tts",
"ttsvoicename": "",
"ttsconfig": "",
"ttsengine": "",
"ttsvolume": 0,
"ttsspeechrate": 0,
"ttspitchrate": 0
},
"privatedata": "test",
"playbacks": [
"欢迎进入测试程序,被叫号码是",
"${destination_number}",
"请说话测试吧",
"test.wav"
],
"sound_file_dir": "E:/sad/",
"pre_tts_text": [
"徐先生",
"2022年12月6日"
],
"log": "create succeed"
}
action 执行的动作
- cti_play_and_detect_speech 放音同时执行语音识别
argument 动作参数
cti_play_and_detect_speech的argument顺序:
vad_min_active_time_ms vad_max_end_silence_time_ms wait_speech_timeout_ms max_speech_time_ms hot_word asr_params appid record_mode record_template record_format,参数说明请看 http://www.ddrj.com/smartivr/robot.html#ASR%E9%85%8D%E7%BD%AE 详细参数文档请看 http://www.ddrj.com/callcenter/asr.html#%E6%94%BE%E9%9F%B3%E7%9A%84%E5%90%8C%E6%97%B6%E6%89%A7%E8%A1%8CASR%E8%AF%86%E5%88%AB appid这个参数非常重要,必须把请求里面appid参数,放到这里。不然会导致接受不到文本输入(一句话识别)请求。
tts tts的配置说明,create的时候必须设置tts,后面可以不设置,会使用最后一次设置的。参数说明请看
http://www.ddrj.com/smartivr/robot.html#TTS%E9%85%8D%E7%BD%AE如果需要对接自己的tts接口,ttsurl设置为 http://tts服务IP/tts,cti 会自动 把 tts参数加在这个URL后面,
http://tts服务器ip/tts?config=&voice=&volume=0&speechrate=0&pitchrate=0&engine=&text=你好这里是顶顶通软件类似这样。tts服务器返回tts转换后的声音文件(8000hz16位单声道的wav格式),浏览器测试可以下载到可播放的声音文件就可以。如果需要对接实时返回流的tts,改成ws://tts服务器地址:wsport/tts, URL参数不变,tts服务器实时返回8000hz16位单声道pcm声音流就可以。sound_file_dir 声音文件路径,如果放音的是声音文件可以这个参数指定文件路径。后面可以不设置,会使用最后一次设置的。
dtmf_terminators DTMF终止符,any:任意字符,none:无终止符,max=最大输入DTMF个数,比如max=16,只有设置了DTMF终止符,才会处理DTMF输入,如果要放音的时候忽略按键,加上
noplay,前缀。(DTMF就是电话按键的别称)quickresponse 设置为true,识别到文字就提交。设置为false,一句话结束才提交。
silent 设置为true,说话停止时先给一个文本输入s回掉。
playbacks 放音内容,支持变量,文字,录音文件等放音,详细说明请看 http://www.ddrj.com/smartivr/robot.html#%E6%94%BE%E9%9F%B3%E6%96%87%E4%BB%B6
privatedata 可以设置一个任意字符串,后续请求会送回这个数据,类似回调参数
log 如果需要输出日志到cti模块可以设置log。方便通过日志查看问题
pre_tts_text 需要预先tts的文本,因为TTS比较慢,可以对变量预先TTS,这样放音的时候,就已经TTS好了,不会卡顿。只有create的时候才支持pre_tts_text这个参数。
输入回调(input.text),说话或按键时执行的回调。
cti –> web (请求)
{
"timestamp": 1658152582127483,
"input_type": "text",
"input_args": "F你好",
"input_start_time": 1658152579338493,
"input_duration": 2779,
"play_progress": 0,
"callid": "27d36dee-a03f-40d2-b92e-2872c9057c21",
"appid": "1e89c6c7-e03b-4988-be0a-7eee25df8fa7",
"method": "input",
"privatedata": "test",
"record": "C:/src/utility/freeswitch/x64/Debug/recordings/2022-07-18/27d36dee-a03f-40d2-b92e-2872c9057c21_1.wav"
}
- timestamp 当前微秒的时间戳
- input_type 输入类型
- text ASR
- dtmf 按键
- complete 动作执行完成
- input_args 输入参数,input_type TEXT时asr识别结果(如果没命中关键词可以不处理),DTMF时按键内容。COMPLETE是完成输入参数 ,必须返回新动作。
- text:asr识别结果前缀说明
- 前缀F:一句话识别完成
- 前缀E:ASR错误
- 前缀S:用户还在说话,实时识别中
- 前缀b:检测到开始说话
- 前缀P:放音时的识别结果(打断模式128和256时放音时候说话才触发)
- 前缀p: 暂停放音的时候等待用户说话超时
- dtmf:dtmf按键内容
- d:未匹配到终止符
- D:已经匹配到终止符
- complete:完成输入参数
- DONE() 输入完成,DONE(F:识别内容1F:识别内容2)
- TIMEOUT() 输入超时了,TIMEOUT(F:放音时候的识别内容S:超过最大说话时间了)。如果没检测到声音就是TIMEOUT()。TIMEOUT(S:识别内容)这样的也代表一次ASR调用,也要对ASR进行计费。
- ERROR() 遇到错误
- BREAK() 外部程序执行了uuid_break
- HANGUP() 通话挂断了
- text:asr识别结果前缀说明
- input_start_time 输入开始时间,比如说话开始时的时间(微秒的时间戳)
- input_duration 输入持续时间 ,比如说话的持续时间(毫秒)
- play_progress 当前已经放音的时间(毫秒),暂停放音后这个值就不变化了。
- play_stop_time 当前放音结束的时间(微秒的时间戳),如果当前在放音中,这个时间就是0
web –> cti (响应)
{
"action": "cti_play_and_detect_speech",
"argument": "'1' '32' '0' '0.3' '127.0.0.1:9988' '120' '800' '5000' '20000' '' '' '8c44580b-ee09-4eaf-9641-d54c0466d810' '1' '${strftime(%Y-%m-%d)}' 'wav'",
"privatedata": "test",
"playbacks": [
"机器人放音内容"
],
"log": "自定义日志"
}
输入回调(input.complete),动作执行完成时执行的回掉,比如等待按键或者说话超时。
cti –> web (请求)
{
"timestamp": 1658156884760552,
"input_type": "complete",
"input_args": "TIMEOUT()",
"input_start_time": 1658156884740422,
"input_duration": 0,
"play_progress": 0,
"callid": "8ea0531c-18a6-4b5d-900f-ca5a34dfb5b6",
"appid": "258c056b-205f-4822-82af-52e0cf60c970",
"method": "input",
"privatedata": "test",
"record": ""
}
web –> cti (响应)
{
"action": "hangup",
"privatedata": "test",
"playbacks": [
"谢谢你的测试,再见"
],
"log": "自定义日志"
}
这个例子是执行挂机,实际上可以继续执行cti_play_and_detect_speech,继续对话。
伴随转人工的例子(人工接通前不切断机器人对话)
cti –> web (请求)
{
"timestamp": 1658200433683591,
"input_type": "text",
"input_args": "F转人工",
"input_start_time": 1658200428163288,
"input_duration": 5509,
"play_progress": 0,
"callid": "00075aa2-f6e6-4bf9-ad5a-2eb67534ae7c",
"appid": "4617bce4-4048-4037-8165-74ef1f67947b",
"method": "input",
"privatedata": "test",
"record": "C:/src/utility/freeswitch/x64/Debug/recordings/2022-07-19/00075aa2-f6e6-4bf9-ad5a-2eb67534ae7c_2.wav"
}
web –> cti (响应)
{
"action": "cti_play_and_detect_speech",
"argument": "'1' '32' '0' '0.3' '12.0.0.1:9988' '120' '800' '5000' '20000' '' '' '4617bce4-4048-4037-8165-74ef1f67947b' '1' '${strftime(%Y-%m-%d)}' 'wav'",
"privatedata": "test",
"playbacks": [
"正在为你转接人工,人工介入前,机器人可以继续和你对话,请继续说话了"
],
"manual": {
"linegroup": "2001",
"answer_stop_robot": true,
"beep_time": 1000,
"rest_time": 5000
},
"log": "自定义日志"
}
manual (转人工),这个参数只能设置一次,人工介入后,会自动停止机器人对话。
linegroup 通知到坐席组,就是线路组。
报工号方法
{origination_nested_vars=true,api_before_bridge_play='uuid_cti_background ${uuid} http://demo.ddrj.com:9989/tts?text=\\\${employee_id} mfrw'}linegroup/useremployee_id是线路配置的工号变量
answer_stop_robot false:坐席接通后进入监听模式,按DTMF*才进入通话模式 ,true:坐席接通后机器人自动停止对话 。
beep_time 坐席接通时的滴声时间,单位毫秒。
rest_time 坐席接完一个电话后的休息时间,单位毫秒。
直接转人工例子(人工接通前就切断机器人对话)
cti –> web (请求)
{ |
web –> cti (响应)
{ |
bridge 呼叫分机的命令
argument 转接给user/120 这个分机,{ignore_early_media=true}user/120 忽略原始彩铃(如果需要一直播放自定义彩铃,需要加上这个变量)
报工号方法
{origination_nested_vars=true,api_before_bridge_play='uuid_cti_background ${uuid} http://demo.ddrj.com:9989/tts?text=工号 mfrw'}user/120例子JSON
{
"variables": ["continue_on_fail=true", "robot_response=${variable_originate_disposition}", "robot_result=${variable_last_bridge_proto_specific_hangup_cause}"],
"action": "bridge",
"argument": "{origination_nested_vars=true,api_before_bridge_play='uuid_cti_background ${uuid} http:\/\/demo.ddrj.com:9989\/tts?text=\\\\\\${employee_id} mfrw'}linegroup\/user",
"privatedata": "test",
"playbacks": ["\u6b63\u5728\u4e3a\u4f60\u8f6c\u63a5\u5206\u673a\uff0c\u8bf7\u7b49\u5f85"],
"log": "\u8f6c\u5206\u673a"
}
http://demo.ddrj.com:9989/tts?text=这个是tts地址
playbacks 转分机前播放的提示音
variables
- transfer_ringback=彩铃文件路径
- instant_ringback=true 启用自定义回铃音
- continue_on_fail=true 呼叫分机失败后,不要挂断,返回流程
- robot_response 设置bridge 动作完成参数response映射的变量
- variable_originate_disposition SUCCESS,其他呼叫失败原因
- variable_DIALSTATUS SUCCESS,其他呼叫失败原因,这个变量对部分失败原因进行了改写
- robot_result 设置bridge动作完成输入result映射的变量。
- variable_last_bridge_proto_specific_hangup_cause 返回“sip:挂机代码”
- variable_last_bridge_hangup_cause 返回挂机原因
- variable_sip_invite_failure_status 返回挂机代码
- variable_sip_hangup_phrase 返回挂机代码的文字描述
cti –> web (请求)
呼叫分机失败
{ |
- input_args CALL_REJECTED 呼叫拒绝,更多错误代码看 http://www.ddrj.com/callcenter/cdr.html#freeswitch%E5%B8%B8%E7%94%A8%E5%8F%98%E9%87%8F (sip:具体的sip挂机代码)
cti –> web (请求)
呼叫分机成功(通话结束)
{ |
- input_args SUCCESS转接成功。
盲转
伴随转接和bridge转接都会占用线路,盲转不占用线路,直接向对方发送转接信令,然后挂断电话。
web –> cti(响应)
{ |
- argument 说明 sip:转接号码@对方服务器Ip,可以用变量${sip_network_ip}自动获取对方服务器IP
排队转人工的例子(如果没空闲坐席可以排队等待)
排队详细参数和用法请看 http://www.ddrj.com/callcenter/acd.html#%E8%BF%9B%E5%85%A5%E6%8E%92%E9%98%9F
cti –> web (请求)
{
"timestamp": 1658200433683591,
"input_type": "text",
"input_args": "F排队",
"input_start_time": 1658200428163288,
"input_duration": 5509,
"play_progress": 0,
"callid": "00075aa2-f6e6-4bf9-ad5a-2eb67534ae7c",
"appid": "4617bce4-4048-4037-8165-74ef1f67947b",
"method": "input",
"privatedata": "test",
"record": "C:/src/utility/freeswitch/x64/Debug/recordings/2022-07-19/00075aa2-f6e6-4bf9-ad5a-2eb67534ae7c_2.wav"
}
web –> cti (响应)
{
"action": "cti_acd",
"argument": "8001 10 1",
"playbacks": ["放音不是必须的,可以不放音"],
"privatedata": "acd",
"log": "acd test"
}
- acdname ACD排队名称
- maxwaittime 最大等待时间,单位秒,超过这个时间,没有接通坐席,会强制离开排队。
- 如果需要没空闲坐席不等待,可以把最大等待时间设置为 nowait 。
- 如果需要一直等待永不超时设置为0。
- priority 优先级, 默认3个优先级 0低优先级 1中(默认) 2高优先级别。
cti –> web (请求)
排队超时,就是超过了maxwaittime 时间,没坐席接听
{
"timestamp": 1749096469591046,
"input_type": "complete",
"input_args": "TIMEOUT()",
"input_start_time": 1749096469591046,
"input_duration": 0,
"play_progress": 0,
"play_stop_time": 0,
"callid": "cc6a5ffc-c099-4a66-ac56-cbc9d33a1920",
"appid": "b7c9044e-f012-450c-9866-dfd49920f0f3",
"method": "input",
"privatedata": "acd",
"record": ""
}
转接成功坐席接通后挂机后离开排队
{
"timestamp": 1749096972030624,
"input_type": "complete",
"input_args": "DONE(122.ddt)",
"input_start_time": 1749096967792354,
"input_duration": 4238,
"play_progress": 0,
"play_stop_time": 0,
"callid": "e8f5fcd2-3b33-4350-b186-9dd0b6fe71c4",
"appid": "8c936ed9-f320-41e7-96b2-c61315df3911",
"method": "input",
"privatedata": "acd",
"record": ""
}
排队时来电主动挂断
{
"timestamp": 1749097058371222,
"input_type": "complete",
"input_args": "DONE(caller hangup)",
"input_start_time": 1749097058371222,
"input_duration": 0,
"play_progress": 0,
"play_stop_time": 0,
"callid": "4f249004-1503-4cb2-b1e9-a8053bd64c8e",
"appid": "9a81fbc5-6de2-4d19-97fb-84ebf3278bac",
"method": "input",
"privatedata": "acd",
"record": ""
}
结束流程 (destory),通话结束最后一个执行的回调。
cti –> web (请求)
{
"timestamp": 1658152593247392,
"callid": "27d36dee-a03f-40d2-b92e-2872c9057c21",
"appid": "",
"method": "destory",
"privatedata": "test",
"cause": "send_bye"
}
- cause 结束原因
web –> cti (响应)
{
"log":"destory succeed"
}
动作参数说明
支持FreeSWTICH所有APP,这里只介绍几个cti模块专有的APP
cti_play_and_detect_speech
放音的同时执行ASR识别,详细参数文档请看 http://www.ddrj.com/callcenter/asr.html#%E6%94%BE%E9%9F%B3%E7%9A%84%E5%90%8C%E6%97%B6%E6%89%A7%E8%A1%8CASR%E8%AF%86%E5%88%AB
hangup
挂机,参数就一个挂机原因。可以不设置参数。
cti_acd
进入排队 详细参数请看 http://www.ddrj.com/callcenter/acd.html#%E8%BF%9B%E5%85%A5%E6%8E%92%E9%98%9F
执行动作前放音
"playbacks": ["放音文字", "${destination_number}", "test.wav"] 任意动作都可以通过设置参数playbacks实现执行前放音。比如挂机(hangup)动作添加一个playbacks参数,就可以实现挂机前先放音。
执行动作前执行fs命令(API)
`”commands”:[“uuid_cti_play_and_detect_speech_break_play 534f5291-25bd-4440-af6d-173f26ffd83f”]} 任意动作都可以通过设置参数commands实现执行动作前先执行一个命令。
关键词停止放音(不打断)
关键词打断,就是匹配到关键词就播放新的声音,有一种场景,匹配到关键词停止放音,但是要等待用户说完才播放声音。下面就是描述这种场景的实现方法。
- quickresponse 设置为true,开启实时识别结果输出。
- 打断模式设置不要设置为1或者2,可以设置0,16或者32。 cti_play_and_detect_speech的第二个参数 就是
[打断:【interrupt】0:关键词打断;1:检测到声音打断; 2:有识别结果打断; 3:识别到一句话打断。【关键词打断的可选功能,可以组合使用,比如要使用16和32,就设置48。16: 放音结束后识别到一句话就停止等待。 32: 放音时识别到一句话就不等待(隐含16)。64:放音时检测到声音就暂停放音。】]具体可以参考 http://www.ddrj.com/smartivr/robot.html#ASR%E9%85%8D%E7%BD%AE - 匹配到关键词执行API命令 uuid_cti_play_and_detect_speech_break_play $callid
- 也可以结合 play_progress 参数实现放音时候不允许打断。
放音控制
命令:uuid_cti_fileman <uuid> <speed|volume|pause|stop|truncate|restart|seek>:<+val|-val>
speed 控制放音速度 比如 +1,-1
volume 控制放音音量 比如 +10,-10
pause 暂停放音,再次执行就恢复放音
注意在暂停放音的时候,如果用户后续不在说话(超过wait_speech_timeout_ms 最大等待说话时间),会有一个text输入,前缀p,内容wait_speech_timeout 的回调,通知到接口暂停超时了。可以通过设置通道变量
cti_pause_wait_speech_timeout_ms自定义暂停时最大等待说话时间。{
"timestamp": 1709196090518067,
"input_type": "text",
"input_args": "pwait_speech_timeout",
"input_start_time": 1709196090518067,
"input_duration": 0,
"play_progress": 2480,
"callid": "1ec37ad9-b1fb-4aa4-a2d5-d1761928d89b",
"appid": "6a701aa4-9828-4b4b-8095-397b8ef291e6",
"method": "input",
}
stop 停止放音
truncate
restart 重新开始放音
seek 设置放音位置
设置通道变量
{"variables":["continue_on_fail=true","robot_response=${variable_originate_disposition}","robot_result=${variable_last_bridge_proto_specific_hangup_cause}"] 任意动作都可以添加variables参数,来实现动作执行前设置fs通道变量。
自定义动作完成返回值
可以通过设置通道变量robot_response和通道变量robot_result来实现自定义动作完成输入参数。 “input_type”:”complete”,”input_args”:”${robot_response)(${robot_result})”,比如bridge的例子设置变量”robot_response=${variable_originate_disposition}”,”robot_result=${variable_last_bridge_proto_specific_hangup_cause}”,动作完成输入input:complete CALL_REJECTED(sip:603),查看fs全部通道变量的方法是 fs控制台执行命令 uuid_dump callid ,这样查询到全部通道变量,然后设置你需要的通道变量。
接收DTMF按键
cti_play_and_detect_speech动作时添加"dtmf_terminators":"#"这个参数就可以启用DTMF按键接收,如果需要只接收DTMF按键,不要开启语音识别,只需要把argument的第一个参数改成0,就不会开启ASR语音识别了。
dtmf_terminators DTMF终止符,any:任意字符,none:无终止符,max=最大输入DTMF个数,比如max=16,只有设置了DTMF终止符,才会处理DTMF输入(DTMF就是电话按键的别称),如果需要放音的时候不接收按键,可以添加一个前缀 “noplay,”,比如放音的时候最大接收1个案件就是设置为”noplay,max=1”。如果需要设置最大10位或者#终止设置为”max=10,#”, 如果多个注意顺序必须noplay,然后max=,然后其他。
默认只有符合按键终止符才会停止放音,如果需要不符合按键终止符也停止放音,需要设置打断模式为512。
input_type TEXT和COMPLETE的区别
ASR识别到文字执行input_type=TEXT的回调,前缀S表示还在识别中,如果命中了关键词可以返回新流程动作,前缀F表示说话完成。如不继续等待用户说话,可以返回新流程动作。如果用户没说话或者input_type=TEXT的时候没有返回新流程动作,最大等待时间到达就会执行input_type=COMPLETE回调,这个回调必须返回新流程动作。
外部程序打断
可以调用httpcli接口http://127.0.0.1:88/cli?key=abc&cmd=uuid_break&arg=4cd77bdc-78ae-4f00-9018-b4ffcd395238 arg为要打断的通话callid。打断后回调通知”input_type”:”complete”,”input_args”:”BREAK()”
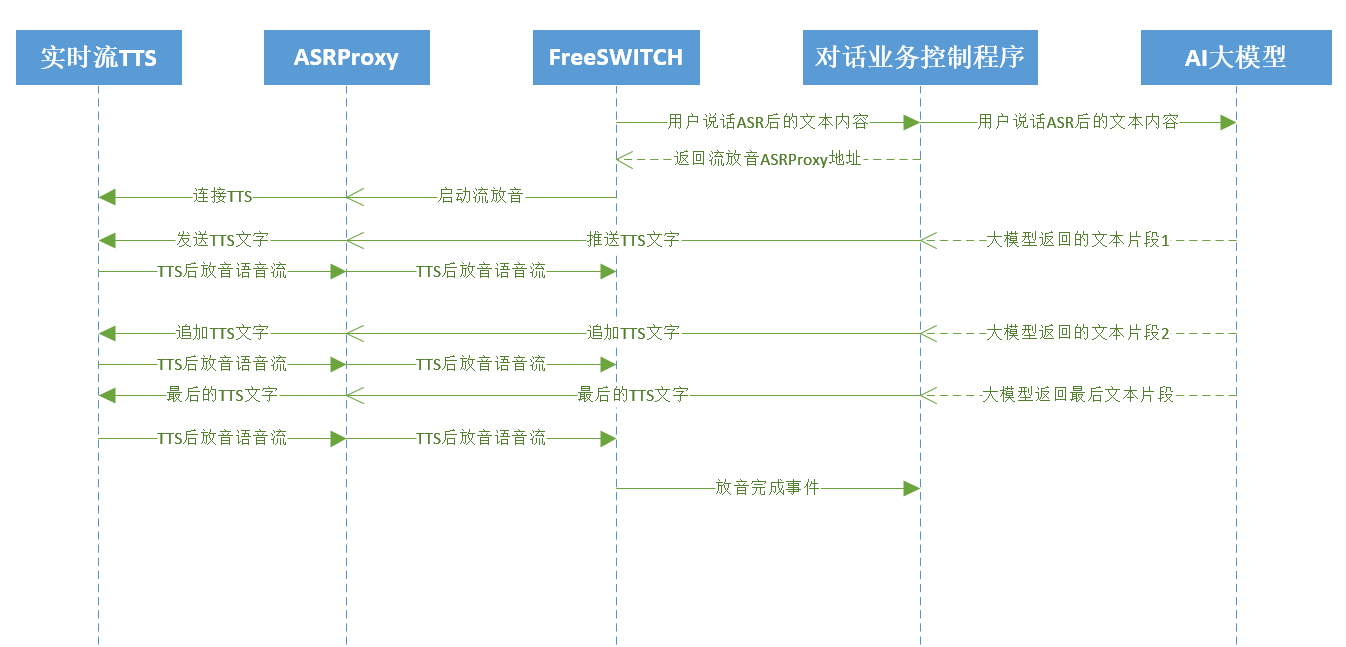
对接大模型注意事项
有的大模型可以逐步返回文本,可以逐步返回给接口放音,让对话更流畅。推荐使用实时流TTS配合大模型,如果普通TTS,建议如下方式改善声音播放
比如大模型返回,第一句话。第二句话。第三句话。
大模型返回了第一句话,就把第一句话返回给接口去放音,返回的动作cti_play_and_detect_speech的参数等待说话时间,设置为0,这样放音完成了就会发送 input_type COMPLETE 请求,收到这个请求,继续返回后续的放音内容。就实现了低延迟放音了。
实时流TTS支持
普通的TTS是一次性提交文字,然后一次性返回的语音流。流TTS可以不断追加提交文字,逐步返回语音流非常适合用来对接大模型。
目前只有对接了cosyvoice和火山引擎的实时流TTS。
tts参数
"tts": {
"ttsurl": "ws://127.0.0.1:9989/tts",
"ttsvoicename": "",
"ttsconfig": "",
"ttsengine": "",
"ttsvolume": 0,
"ttsspeechrate": 0,
"ttspitchrate": 0,
},- ttsurl 设置为 asrproxy的地址,注意实时流TTS是ws,不是http。
放音文本
- cti_play_and_detect_speech动作的playback参数 ,也就是tts文字内容 前面加上”[最大等待文本时间]其他放音内容”,比如”[10000]你好”。如果刚开始没要放音的内容,可以直接把放音文字设置为”[10000]”。
- [10000]的含义是最大等待10000毫秒,如果超时没收到 动态更新文字接口 提交的文字就退出cti_play_and_detect_speech。
动态更新文字接口
- http://127.0.0.1:9989/additiontext?text=文字&finish=0&taskid=appid
- text 要追加到tts的文字
- finish 是否结束文字输入,如果文字已经结束,要把finish设置为true
- taskid 就是对话接口里面的appid,用来知道更新哪个TTS放音的文字。
- http://127.0.0.1:9989/additiontext?text=文字&finish=0&taskid=appid
调用流程图
例子
php
<?php |
java
package com.cs.app.controller; |